Data Engineering
IF5OT7 - 6 ECTS
“A scientist can discover a new star, but he cannot make one. He would have to ask an engineer to do it for him.” – Gordon Lindsay Glegg
Overview
The course aims at giving an overview of Data Engineering foundational concepts. It is tailored for 1st and 2nd year Msc students and PhDs who would like to strengthen their fundamental understanding of Data Engineering, i.e., Data Modelling, Collection, and Wrangling.
Origin and Design
The course was originally held in different courses at Politecnico di Milano (🇮🇹) by Emanuele Della Valle and Marco Brambilla. The first issue as a unified journey into the data world dates back to 2020 at the University of Tartu (🇪🇪) by Riccardo Tommasini, and where it is still held by professor Ahmed Awad (course LTAT.02.007). At the same time, the course was adopted by INSA Lyon (🇫🇷) as OT7 (2022) and PLD “Data”
Learning Objectives
Students of this course will obtain two sets of skills: one that is deeply technical and necessarily technologically biased, one that is more abstract (soft) yet essential to build the professional figure that fits in a data team.
Challenge-Based Learning
The course follows a challenge-based learning approach. In particular, each system is approached independently with a uniform interface (python API). The student’s main task is to build pipelines managed by Apache Airflow that integrates 3/5 of the presented systems. The course schedule does not include an explanation of how such integration should be done. Indeed, it is up for each group to figure out how to do it, if developing a custom operator or scheduling scripts or more. The students are then encouraged to discuss their approach and present their limitations.
Soft Skills
- Build a general overview of the data lifecycle and its problems
- ETL, ELT
- Data Pipelines
- Understand the role of the Data Engineer, as opposed to the more famous figure of Data Scientist.
- Skills required by data engineers
- Fitting in a data team
- Presenting a data project
- Writing a post mortem
Creativity Bonus: the students will be encouraged to come up with their information needs about a domain of their choice.
Hard Skills
After a general overview of the data lifecycle, the course deeps into an (opinionated) view of the modern Data Warehouse. To this extent, the will touch basic notions of Data Wrangling, in particular Cleansing and Transformation.
At the core of the course learning outcome there is the ability to design, build, and maintain a data pipelines.
Technological Choice (Year 2024/25): Apache Airlfow
Regarding the technological stack of the course, modulo the choice of the lecturer, the following systems are encouraged.
- Data Formats
- JSON, CSV
- Parquet
- Relational Databases
- Postgres
- Document Databases
- MongoDB
- Columnar Stores
- DuckDB
- Key-Value Stores
- Redis
- Graph Databases
- Neo4J
The interaction with the systems above is via Python using Jupyter notebooks. The environment is powered by [[Docker]] and orchestrated using [[Docker Compose]].
Prerequisites
- Git and GitHub
- SQL and Relational Databases
- Python
Classwork
Syllabus
🖐️ = Practice 📓 = Lecture
- Intro Who is the Data Engineer + Data Lifecycle (📓)
- Docker Fundamentals (🖐️)
- Data Modelling (📓)
- ER (basics)
- Dimensional Modelling and Star Schema (basics)
- Data Formats: JSON, CSV, Avro, Parquet (🖐️)
- Data Orchestrations and Data Pipelines (📓)
- Apache Airflow (🖐️)
- Data Wrangling and Cleansing (📓)
- Pandas (🖐)
- Data Ingestion and Document Databases (📓)
- MongoDB (🖐)
- Caching and Key-Value Stores (📓)
- Redis or RocksDB (🖐)
- Querying: (📓)
- Postgres or SQLite (🖐)
- Advanced Querying: Wide Columns Stores and Graph Databases (📓)
- Cassandra or DuckDB
- Neo4J or Memgraph (🖐)
SCHEDULE
| Topic | Day | Date | From | To | Material | Video | Comment | |
|---|---|---|---|---|---|---|---|---|
|
Intro |
📓 |
Wednesday |
2025/09/24 |
16:00 |
18:00 |
|||
|
Docker |
🖐 |
Thursday |
2025/09/25 |
8:00 |
12:00 |
|||
|
Data Wrangling (Pipelines) |
🖐 |
Monday |
2025/09/29 |
14:00 |
18:00 |
|||
|
Data Modeling (OLTP) |
🖐 |
Wednesday |
2025/10/01 |
14:00 |
18:00 |
|||
|
Data Modeling (OLAP) |
📓 |
Monday |
2025/10/06 |
10:00 |
12:00 |
|||
|
Data Modelling (OLAP) |
🖐 |
Monday |
2025/10/06 |
14:00 |
18:00 |
|||
|
Document Stores |
🖐 |
Wednesday |
2025/10/08 |
14:00 |
18:00 |
|||
|
External Talk by Snowflake |
📓 |
Monday |
2025/10/20 |
10:00 |
12:00 |
|||
|
Project In Class |
🖐🖐 |
Monday |
2025/10/20 |
14:00 |
18:00 |
LAST DATE TO REGISTER |
||
|
Key-Value Stores |
🖐 |
Wednesday |
2025/10/22 |
14:00 |
18:00 |
|||
|
Project In Class |
🖐🖐 |
Monday |
2025/11/03 |
14:00 |
18:00 |
|||
|
Graph DBs |
🖐 |
Wednesday |
2025/11/05 |
14:00 |
18:00 |
|||
|
Exam |
✍️ |
Monday |
2025/11/10 |
10:00 |
12:00 |
|||
|
Project In Class |
🖐🖐 |
Wednesday |
2025/11/12 |
14:00 |
18:00 |
|||
|
Project Submission |
🏁 |
Wednesday |
2026/01/06 |
12:00 |
12:00 |
Submission via Repository (it counts the commit at 12:00) |
||
|
Poster Section |
🎭🍕 |
Wednesday |
2026/01/07 |
14:00 |
18:00 |
NB: The course schedule can be subject to changes!
Practices
Exam
The course exam is done in class in the data indicated in the schedule. It will last around 1h. It includes 2-3 bigger topics (data modelling, pipeline design, etc) and 3-5 smaller topics (simple questions about DE in general, eg., what is an ETL?).
You are allowed to bring an 4A paper with all the notes you can fit in it, only requirement is that the notes is Handwritten
Projects
The goal of the project is implementing a few full stack data pipelines that go collect raw data, clean them, transform them, and make them accessible via to simple visualisations.
You should identify a domain, two different data sources, and formulate 2-3 questions in natural language that you would like to answer. Such question will be necessary for the data modelling effort (i.e., creating a database).
“Different” means different formats, access patterns, frequency of update, etc. In practice, you have to justify your choice!
If you cannot identify a domain yourself, you will be appointed assigned on by the curt teacher.
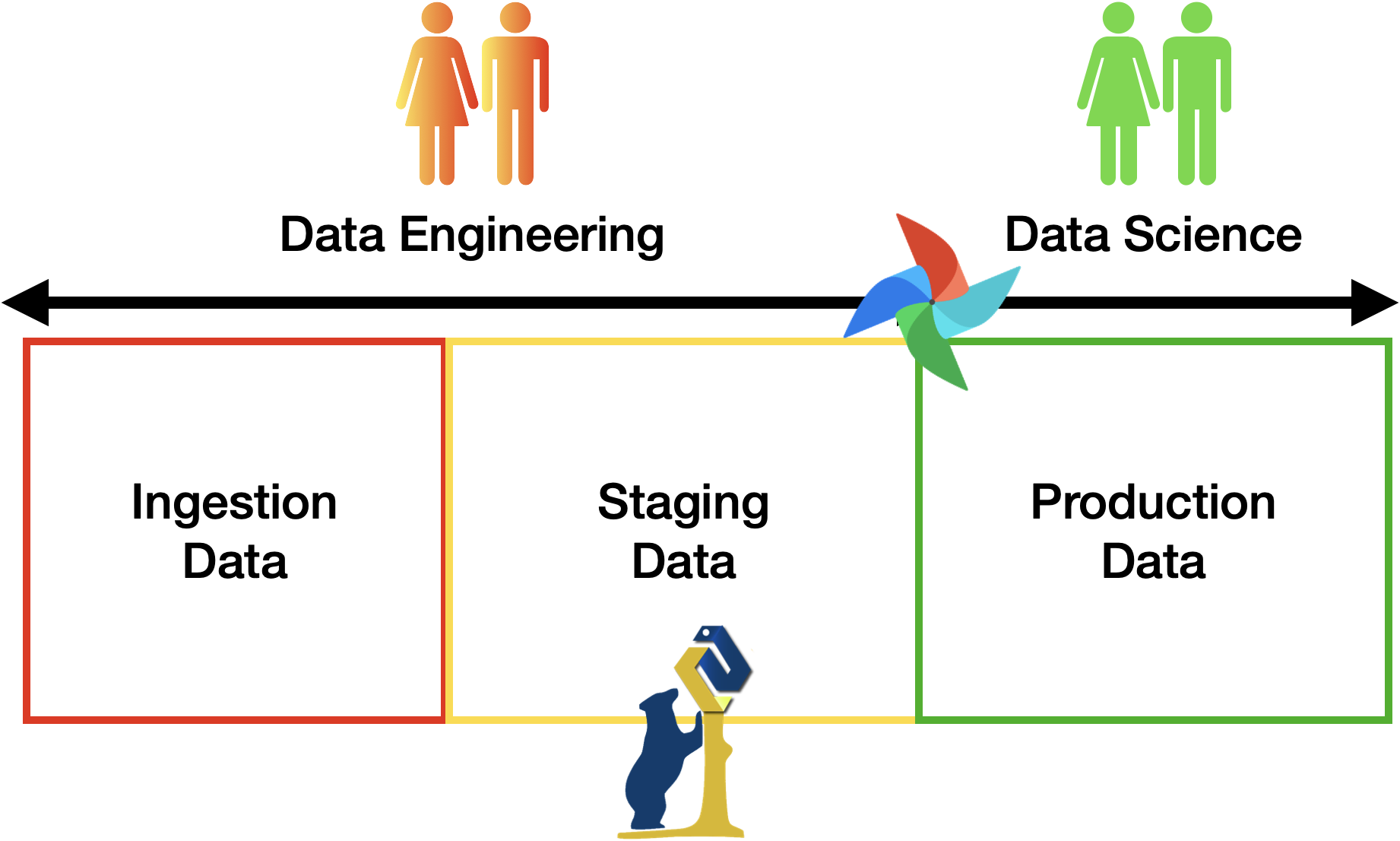
The final frontend can be implemented using Jupyter notebook, Grafana, StreamLit, or any software of preference to showcase the results. THIS IS NOT PART OF THE EVALUATION!
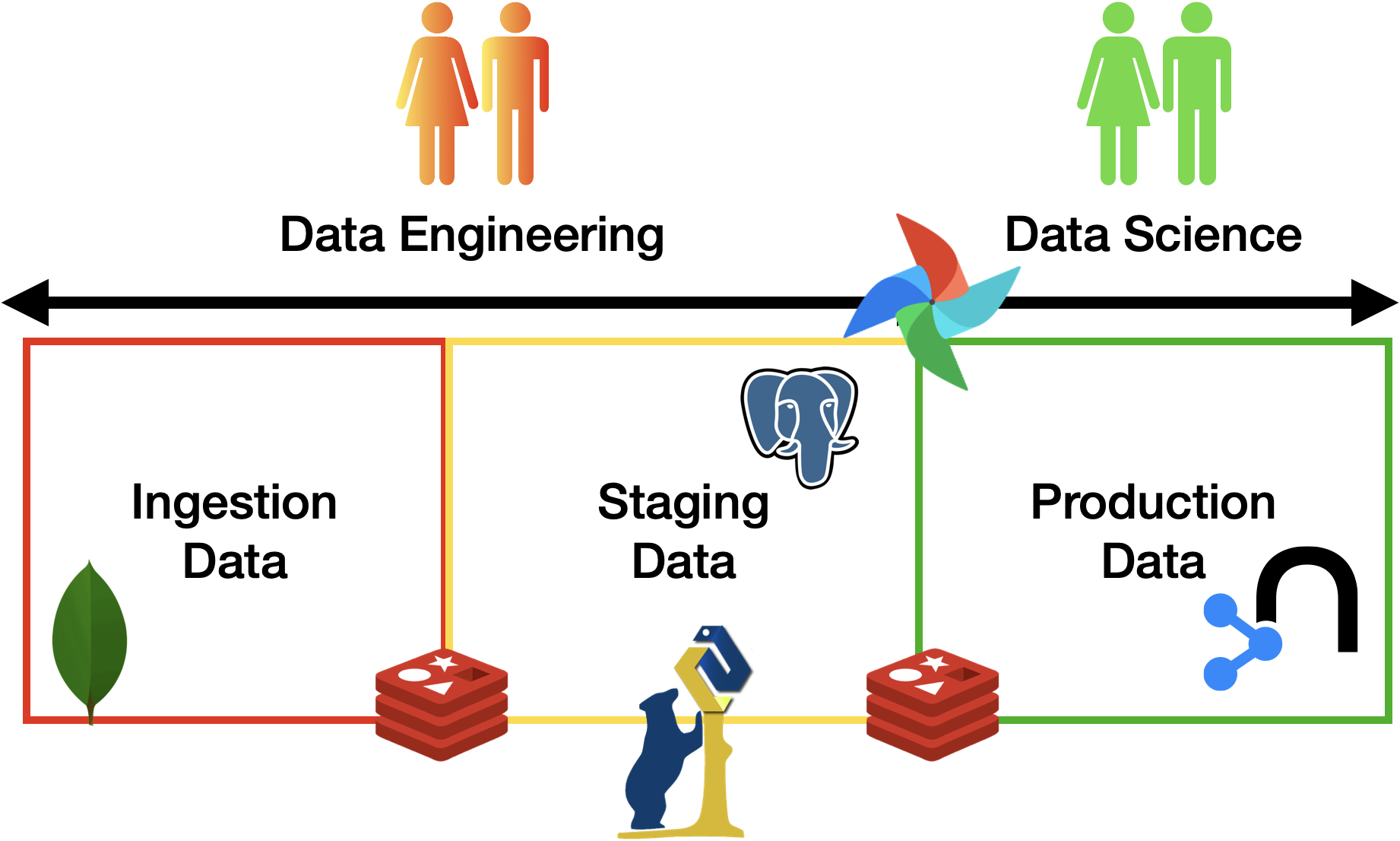
The project MUST include all the three areas discussed in class (see figure above), i.e., ingestion of (raw) data, staging zone for cleaned and enriched data, and a curated zone for production data analytics. To connect the various zones, you should implement the necessary data pipelines using Apache Airflow. Any alternative should be approved by the teacher. The minimum number of pipelines is 3:
- A first pipeline is responsible to bring raw data to the landing zone. Such pipeline is supposed to ingest data from the source identified at first and bring them to a transient storage.
- A second pipeline is responsible to migrate raw data from the landing zone and move them into the staging area.
In practice, the second pipeline is supposed to
- clean the data according to some simple techniques saw in class (extra techniques are welcome yet not necessary)
- wrangle/transform the data according to the analysis needs (the questions formulated at first)
- enrich the data by joining multiple datasets into a single one.
- persist data for durability (the staging zone is a permanent): i.e., resit to a reboot of your (docker) environment.
- The third pipeline is responsible to move the data from the staging zone into the production zone and trigger the update of data marts (views). Such pipeline shall perform some additional transformation and feed the data systems of choice for populate the analysis.
- The production zone is also permanent and data shall be stored to prevent loss.
- such pipeline is also responsible to launch the queries implemented according to one of the analytics languages of choice (SQL/Cypher)
- If you are using SQL, the final database should follow the star schema principles
- for the graph database instead it is sufficient to implement the queries.
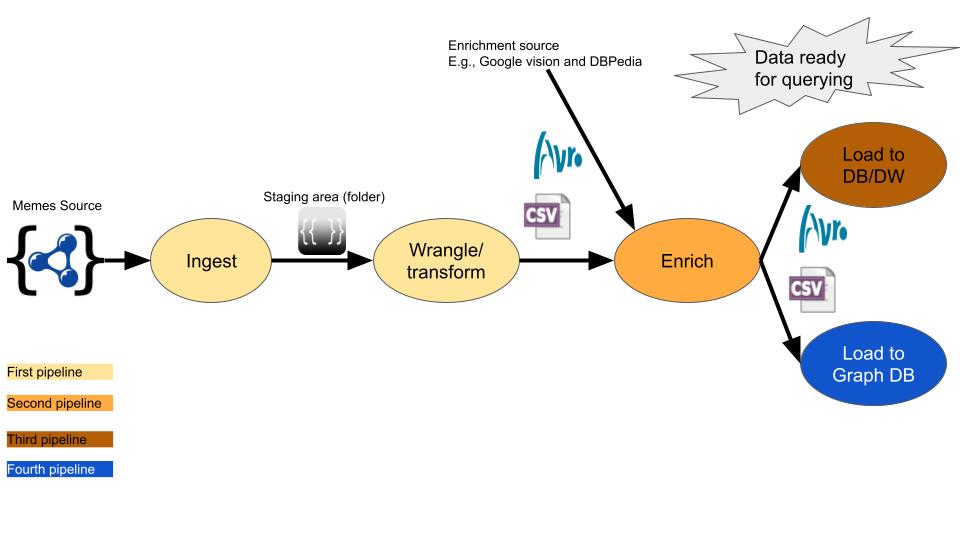
The figure below is meant to depict the structure of the project using the meme dataset as an example.
Project Minimal Submission Checklist
-
repository with the code, well documented, including:
- docker-compose file to run the environment
- detailed description of the various steps
- report in the Repository README with the project design steps (divided per area), a guide how to run it, and consideration relevant to understand it.
- Example dataset: the project testing should work offline, i.e., you need to have some sample data points.
- slides for the project poster. You can do them too in markdown too.
Project grading 0-10 + 5 report (accuracy, using proper terminology, etc) + 5 for the poster.
Increasing Project Grade
The project grading follows a portfolio-based approach, once you achieved the minimum level (described above), you can start enchancing and collect extra points. How?
- +1: Include in the pipelines any tool discussed during the course
- Examples: Redis for cashing, MongoDB for ingestion, Neo4j as alternative to the star schema, etc.
- Requirement: It has to be used properly, always better to double check with teacher.
- +1: Discuss one of the theoretical topics from the course, e.g., add considerations about governance, privacy, etc
- Requirement: It should be included in the report and the poster.
- +2: Using any Data Engineering tool not explained during the course
- Requirement: It should be state of the art tooling.
- Every extra should be approved
- Example: using Kafka for ingestion and staging (also + docker)
- +X: Creativity section
- Ask questions: can get extra points if we do this?
- Examples: data viz, serious analysis, performance analysis.
![]()
![]() Project Registration Form (courtesy of Kevin Kanaan)
Project Registration Form (courtesy of Kevin Kanaan) ![]()
![]()
Pre-Approved Datasets
- Meme Dataset NOTE: analyses MUST SUBSTANTIALLY differ from the example!
- China Labour Bulleting
- GDELT (Real-Time)
- Aria Database for Technological Accidents (French Government, requires registration)
- Fatality Inspection Data
- Wikimedia Recent Changes (or others) (Real Time)
- Wikipedia:
Example Projects From Previous Years
FAQ
-
While ingesting the data do we pull it from the internet or download it on our computer and then import it?
- The ingestion part is about downloading and fetching the data so go get it on internet.
-
Do we filter the data in ingestion?
- It depends, sometimes you may want to filter the data, especially when sensitive data is collected adn should be censored / removed.
-
Should data be persistent in the staging phase?
- Yes, if staging stops at any moment, progress should not be lost/
-
Should data be persistent in the ingestion phase?
- It’s not mandatory, but keep in mind that persisting data comes with its own challenges, you might risk ending up with duplicate saved data.
-
What is the data goal at the end of the staging phase?
- At the end of the staging phase you should only have clean data. ie: no data in pulled from there leads to an error
Related Books
- Foundation of Data Engineering
- Data Pipelines with Apache Airflow
- Designing Data Intensive Applications
- Seven Databases in Seven Weeks
Previous Editions
Enjoy Reading This Article?
Here are some more articles you might like to read next: